Day 2 (45m)
A.I. Party Tricks: Round 2 (5m)
Teach A.I. to display a .gif of a rabbit eating when you pretend to eat food.
Skip the tutorial and follow along with the facilitator and your cohort
Teaching A.I (20m)
Just like humans, machine learning systems benefit from tailoring your teaching. Much of this section will be spent creating a "lesson plan" that fits the tasks and role you designed for your A.I. in the previous section.
Supervised vs. Semisupervised vs. Unsupervised vs. Reinforcement
Some students need to be told the answers, others work well independently, while still others respond to good/bad grades. That also describes the spectrum of human involvement with machine learning.
Supervised learning means the data is provided along with the correct answer (i.e., label). "Here's 1,000,000 recordings of people talking; they all said 'OK Google'." A listing of smartphone specs labelled with their sale price could be provided to a reseller assistant.
Unsupervised learning means no answer is given; the A.I.'s job is to find groupings. "Here's 1,000,000 recordings of people talking. Group together instances of the same words." Patient profiles could be fed into a doctor's assistant.
Semisupervised learning means no answer is given; but after the A.I. sorts it into groupings, at least part of that data is labelled with the correct answer. "Here's 1,000,000 recordings of people talking. Now that you've grouped together instances of the same words, here's what those words are." Human faces could be fed into a mood detector, and then the groupings labelled with emotions like "happy" or "sad".
Reinforcement learning is gamification of the learning process. It is assigning points (positive and negative) to certain events, and then letting the A.I. create it's own policy that will maximize its points. "Self Driving Car Rubric: Getting to destination: +10 points. -1 point for every minute late. -1,000 points for breaking law, -10,000 points for damaging property. -1,000,000 points for hurting a person."
Please fill out the "Supervised..." & "Why" fields.
Batch vs. Online
"Feeding" data to machine learning systems takes two forms. Batch learning refers to taking the entire set of training data and running it through the system. If you get more data, you reset the entire system, then batch learn from the new (and slightly larger) data set. This can waste a lot of computing resources (and time) if you constantly have new data you want to try. But for static (or relatively small) data sets it works well. Think of batch learning as cramming for a final.
Online learning means the A.I. is built to constantly accept and learn from new data. It doesn't have to re-process all the old data to incorporate additional training data. This works great when conditions may be changing rapidly or computing resources may be limited. An embedded medical device meant to monitor health would be best served using this type of learning.
Please fill out the "Batch..." & "Why" fields.
Instance vs. Model-based
Machine learning systems can take one of two types of approaches to predicting answers. Instance-based learning is like stereotyping on steroids. It assumes an input must be like the thing it is the most similar to. "You look like all the pictures of a giraffe, you must be a giraffe." "Your purchase history of bottles, board books, and diapers are most similar to what parents bought, therefore you must be a parent."
Alternatively, model-based learning is about endlessly tweaking parameters to make predictions. It pairs features with parameters, then unites those pairs in a formula to return a prediction. It seeks an ever-better value for those parameters that produces the most accurate predictions. For example, in trying to predict the weather, how much should the day of the year, the temperature, the pressure, etc. influence the prediction? Perhaps counter-intuitively, more parameters are not always better. A model based on the weather yesterday could probably perform pretty well.
Please fill out the "Instance..." & "Why" fields.
A.I. Algorithms (10m)
Algorithms are the particular flavor of logic your A.I. will use to learn. A very brief explanation of a few popular algorithms are provided as an introduction to the possibilities.
Neural Networks

Source: Microsoft Azure Machine Learning; Neural Network in Azure ML
Win an A.I. race through traffic
You have 5 total "points" to divide among the "lanesSide", "patchesAhead" and "patchesBehind" variables. These set the field of vision for the car; what do you think would best help a car navigate traffic? (do not cheat and add more "trainIterations")! Then click "Run Training" and "Start Evaluation" run.
Compare your top speed to others in your cohort.
"DeepTraffic" is an example of a neural network. These algorithms are designed to mimic our own brains synapses with layers of simple connections strengthening or weakening over time. These are highly effective when you need emergent or evolving behavior.
SVM

Source: Open CV; Introduction to Support Vector Machine
A Support Vector Machine (SVM) creates borders around your data that give you the biggest buffer between groupings of data. These work well for classification problems.
Random Forests
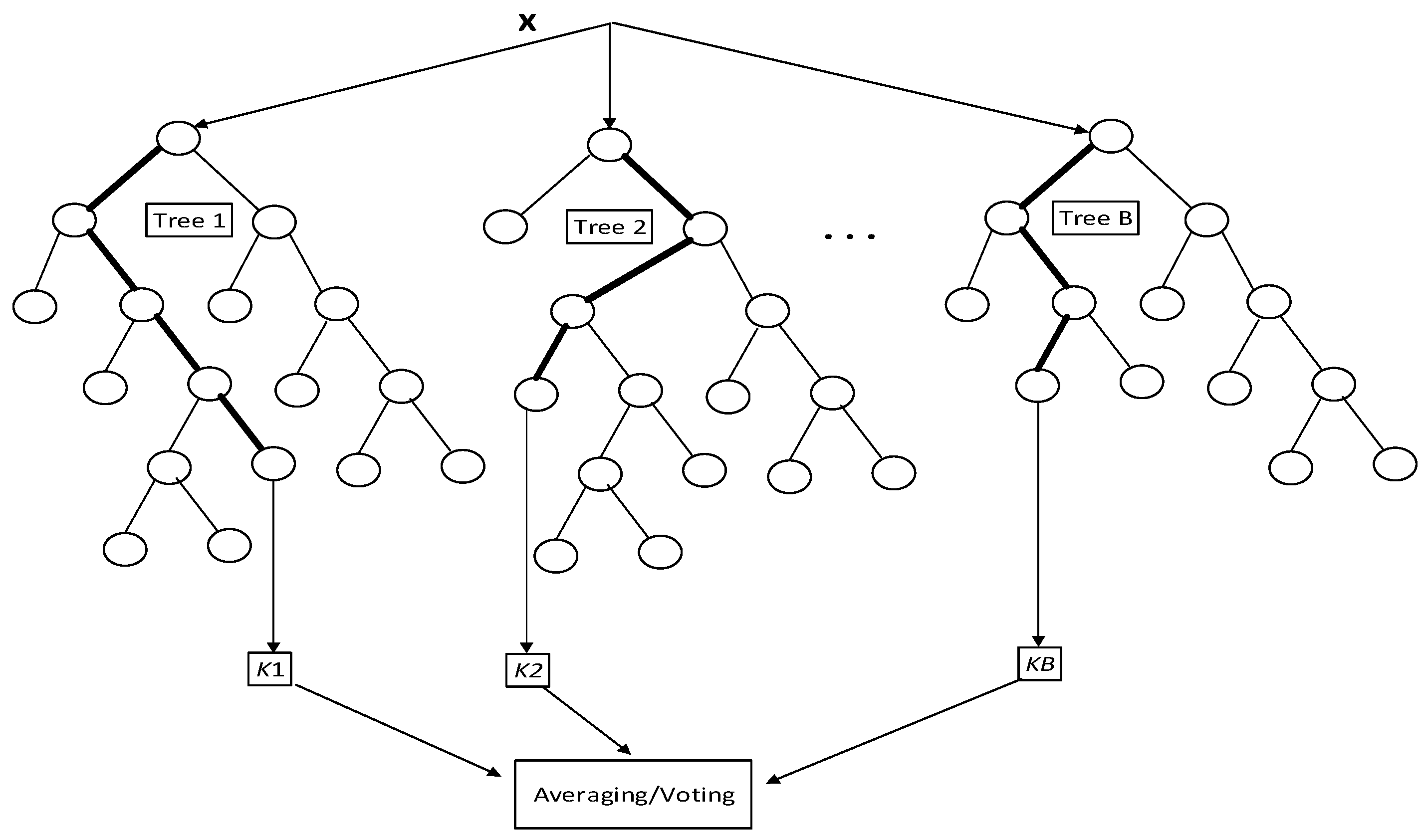
If you combine a bunch of different decision trees (if true, check this, if false check this ... repeat) you create a "Random Forest". The idea is that while one decision tree could get the wrong answer; it is much less likely the combined/collective decision of many decision trees will be wrong. If there is a prevalence of outliers that could make any single method unreliable, random forests can help prevent mistakes by the A.I.
k-Means

Source: Easy Solutions; Machine Learning Algorithms Explained – K-Means Clustering
If you don't have labels for your data (i.e., unsupervised) then the k-Means algorithm can segregate clusters/groupings in your data. It hunts for the total number of clusters and the center point of each cluster.
Please fill out the "Algorithms..." field.
A.I. Maintenance (10m)
Data Plan
With the strategy for training your A.I. coming into focus, it is a good time to circle back and explicitly define the data requirements of your A.I. Refer back to the first section "Data & Features" if needed.
Please fill out the "Data sources..." field with where you will get your data, what features it will contain, and how often you will get it.
Validation
Validate the effectiveness of A.I. with metrics. Precision gives you confidence in the accuracy of the solutions the A.I. provides. Recall gives you confidence in the perceptiveness/awareness of the A.I. Consider the consequences of being wrong (precision) and the consequences of the A.I. not being confident enough to provide a guess (recall). Improving precision will often sacrifice recall (and vice versa). The tricky machine learning systems must have high marks in both metrics: a nuclear missile detection system raising a false alarm (insufficient precision) or failing to notice a missile (insufficient recall) would be disastrous either way.
Please fill out the "A.I. validation..." field with who will validate it, how often, and the minimum precision and recall % expected from the A.I. for it to be viable.
Closing Caution
Machine learning is incredibly powerful and expands what A.I. can do. But, the "technical debt" of maintaining these systems can quickly grow exponentially if poor quality data influences the system, if irrelevant features are left in the data, if multiple algorithms are 'glued' together, if configurations become more complex than the algorithms, etc. Do not be fooled into thinking initial short-term success is sustainable for the A.I. without careful monitoring and maintenance.
A.I. Utilization Plan Complete!
Congrats; please go to the follow-up section to help measure the value of this course.